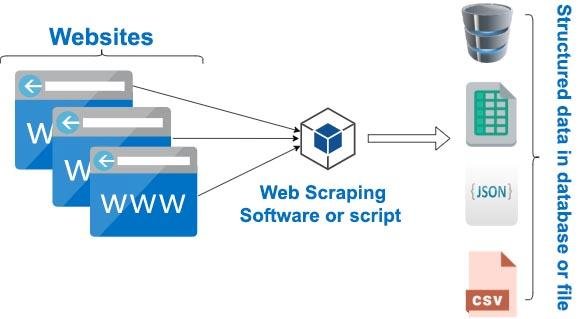
Web Scraping/Crawling, bir -ya da daha fazla- web sitesindeki verileri ayıklamak ve uygulama kullanıcılarına uygun hale getirme tekniğinin adıdır. Türkçe’ye Web Kazıma olarak geçse de yaygın olarak web scraping ya da web crawling terimleri kullanılır.
Kullanım Alanları
İnternet üzerinde birçok veri bulunur. Dağıtık halde bulunan bu verileri ayıklayarak yapısal olarak daha düzgün bir hale getirip kullanabiliriz. Web Scraping kullanım alanlarına örnek olarak
- Haber sitelerindeki haberleri çekip makine öğrenmesi(machine learning) eğitimlerinde,
- Bankaların web sitelerinden döviz bilgilerini çekip karşılaştırma ve analizinde,
- E-Ticaret sitelerinde satılan ürünlerin fiyatlarını çekip karşılaştırma ve analizinde,
- Projenizde kullanmak üzere bir sitedeki verileri çekip sonucu JSON dönen bir API geliştirmesinde,
- Emlak sitelerindeki belirli bölgelere ait ilanların çekilip excel’e dönüştürülmesinde,
- Sosyal Medyadaki içeriklerin çekilmesinde,
- Rehber sitelerindeki firmaların bilgilerinin excel’e dönüştürülmesinde,
Bunun gibi daha onlarca alanda kullanımına örnek verebiliriz. Şimdi gelelim nasıl yapacağımıza.
Web Scraping Nasıl Yapılır?
Web Scraping yapabilmek için iki yöntemimiz var. Bunlardan biri sitenin kaynak kodunu indirmek ve üzerinde ayıklama işlemi yapmak, ikincisi ise bir kullanıcı gibi siteyi tarayıcıda açıp ilgili alanlara tıklayan ve gerekli verileri toplayan bir yapı kurmak. Bu yöntemleri belirlerken, veri çekeceğimiz web sitesinin yapısına göre karar veririz. Ben genelde daha stabil ve kolay olduğundan ilk yöntemi tercih ediyorum. Bu kontrolü yaparken;
- Sitenin kaynak kodunda çekmek istediğim verilerin olup olmadığı kontrol edilir.
- Taracıyı dışında başka bir araç kullanarak dönen HTML içinde çekilecek verilerin olup olmadığı kontrol edilir.
- Eğer kaynak kodunda yoksa tarayıcıda Chrome Dev Tools açarak Network tab’ında bu verinin nasıl çekildiği kontrol edilir.
Bu maddelerden biri sağlanıyorsa ilk yöntemi seçebiliriz. Eğer sağlanmıyorsa bu kez ikinci yöntemle ilerlememiz gerekir.
Biz bu makalede ilk yöntemi kullanacağız. Kaynak kodu indirdikten sonra ayıklama işlemlerini iki farklı şekilde göreceğiz. Bu yazının devamında Regex kullanarak bu işlemi nasıl yapacağımızı göreceğiz. İkinci yöntem olan cheerio modülünü kullanarak web scraping işlemini ise ayrı bir makalede gerçekleştireceğiz.
Veri Çekme
Öncelikle veri çekeceğimiz adres: https://www.qnbfinansbank.enpara.com/hesaplar/doviz-ve-altin-kurlari
Bu adresten Dolar, Euro ve Altın’ın alış ve satış bilgilerini çekip bir JSON elde edeceğiz. Ulaşmak istediğimiz JSON formatı aşağıdaki gibi olacak.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
{
usd: {
sell:13.719,
buy: 13.195
},
eur: {
sell: 15.675,
buy: 14.855
},
gold: {
sell: 810.829,
buy: 768.251
}
};
Bir sitenin HTML kodlarını çekmek için request-promise modülünü kullanabileceğimiz modüllerden sadece biridir. Bir modülü kullanabilmek için öncelikle kurmamız gerektiğini biliyoruz. request-promise modülünü kullanabilmek için request modülünü de kurmamız gerektiğinden ikisini kuruyoruz.
1
npm i request request-promise
Bir javascript dosyası oluşturup modülü import edelim.
1
const request = require("request-promise");
Ardından bu modülü kullanarak yukarıdaki adrese bir GET isteği gönderelim.
1
2
3
4
5
6
7
8
9
10
11
12
const request = require("request-promise");
getExchangeInfo();
async function getExchangeInfo() {
let body = await request({
url: "https://www.qnbfinansbank.enpara.com/hesaplar/doviz-ve-altin-kurlari",
method: "GET"
});
console.log(body);
}
HTML verisini çekip body değişkenine atadık. Artık bu yığın içinden ihtiyacımız olan verileri ayıklayabiliriz.
Regex ile Web Scraping
Veri ayıklama geliştirmesini yapmadan önce her zaman web sitesininin kaynak kodlarını regex101’e aktarıp regex’i burada oluştururum. Bu işlem beni geliştir > çalıştır > test döngüsünden kurtardığı için oldukça büyük zaman kazandırır. Hadi başlayalım.
İlk adımımız sayfaya tarayıcıdan girip sağ tık Kaynağı Görüntüle(View Source Code) ile sayfanın kaynak kodlarını açmak.
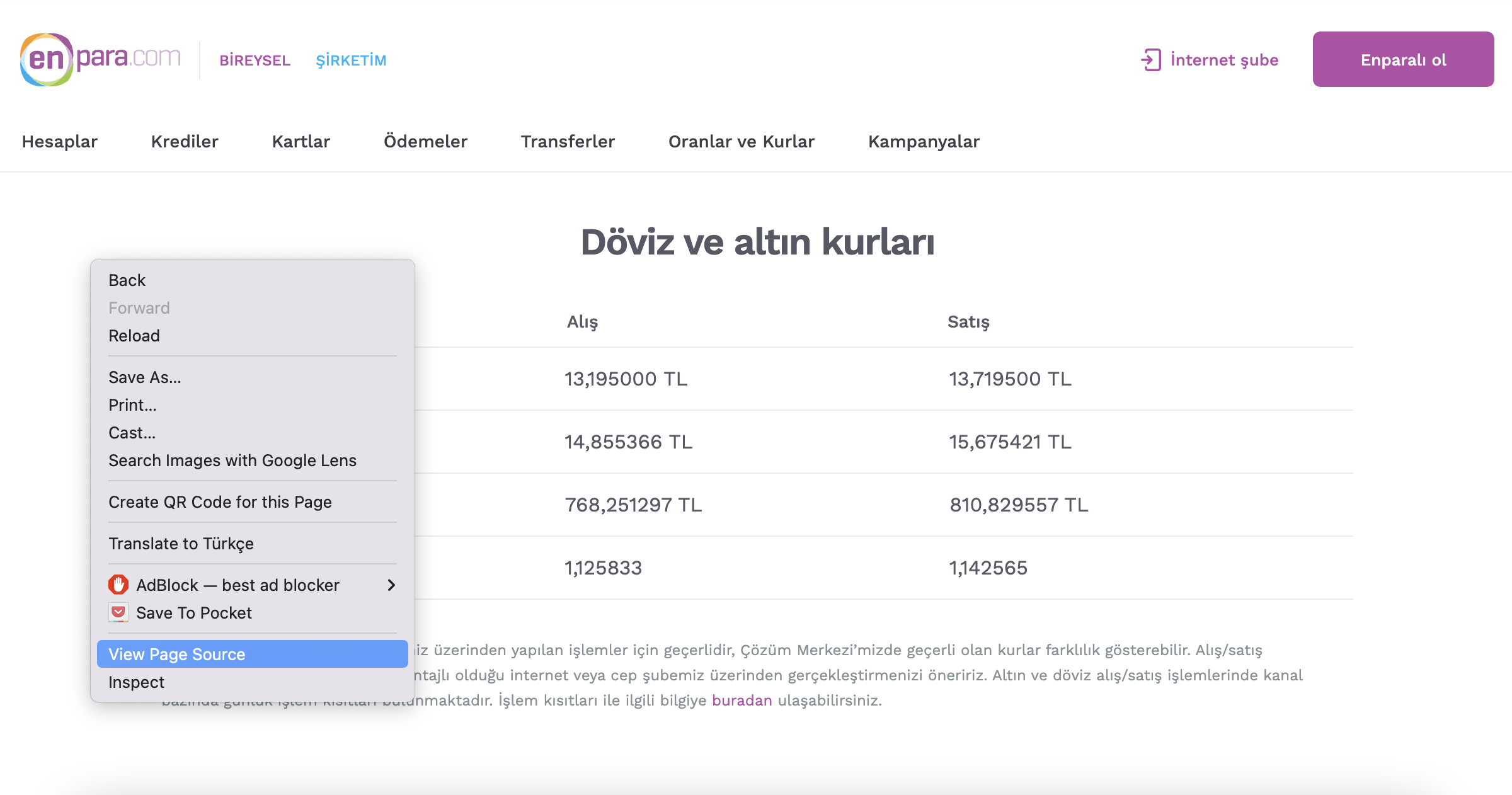
Ardından kaynak kodlar arasında ayıklayacağımız değerlerin yerini kaynak kod içinde arama yaparak(Windows için: Ctrl+f, mac için Cmd+f) tespit edelim.

Ardından kodların tamamını regex101‘e yapıştıralım. Bazen sayfaların kaynak kodları çok kalabalık oluyor bu durumda ayıklamak istediğimiz alanının üstten ve alttan biraz fazlasını kopyalayıp alabiliriz. Eğer sadece ayıklamak istediğimiz alanı alırsak tam sayfa üzerinde regex’i çalıştırdığımızda farklı bir yerle eşleşebilir bu da sonucun doğru dönmemesine neden olur.
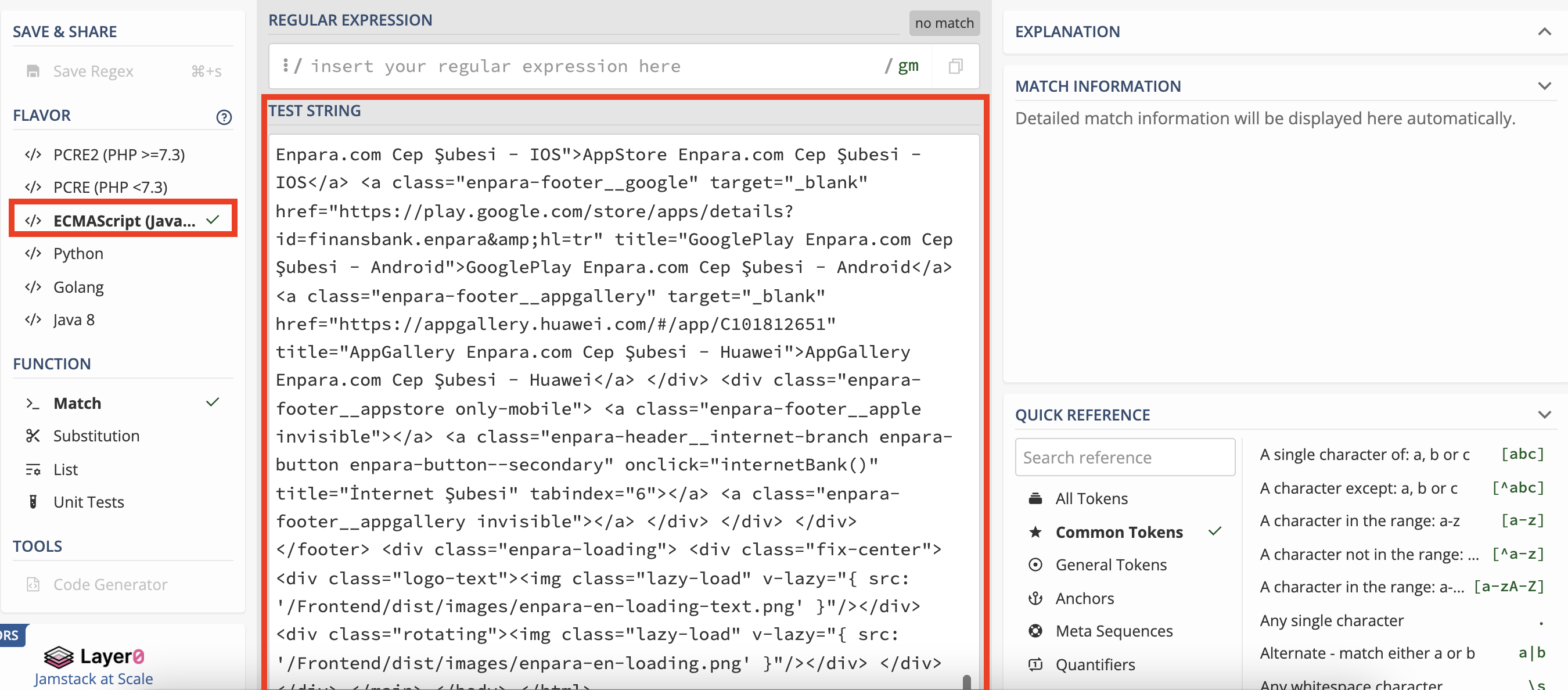
Özellikle sol tarafta ECMAScript(Javascript)’in işaretli olduğundan emin olalım ki geliştirme aşamasında yazdığımız Regex’te bir sorun çıkmasın. Ortamımız hazır, artık regex’i yazmaya başlayabiliriz. İlk olarak Regex alanına USD yazıp kaç tane yakaladığına bakalım.
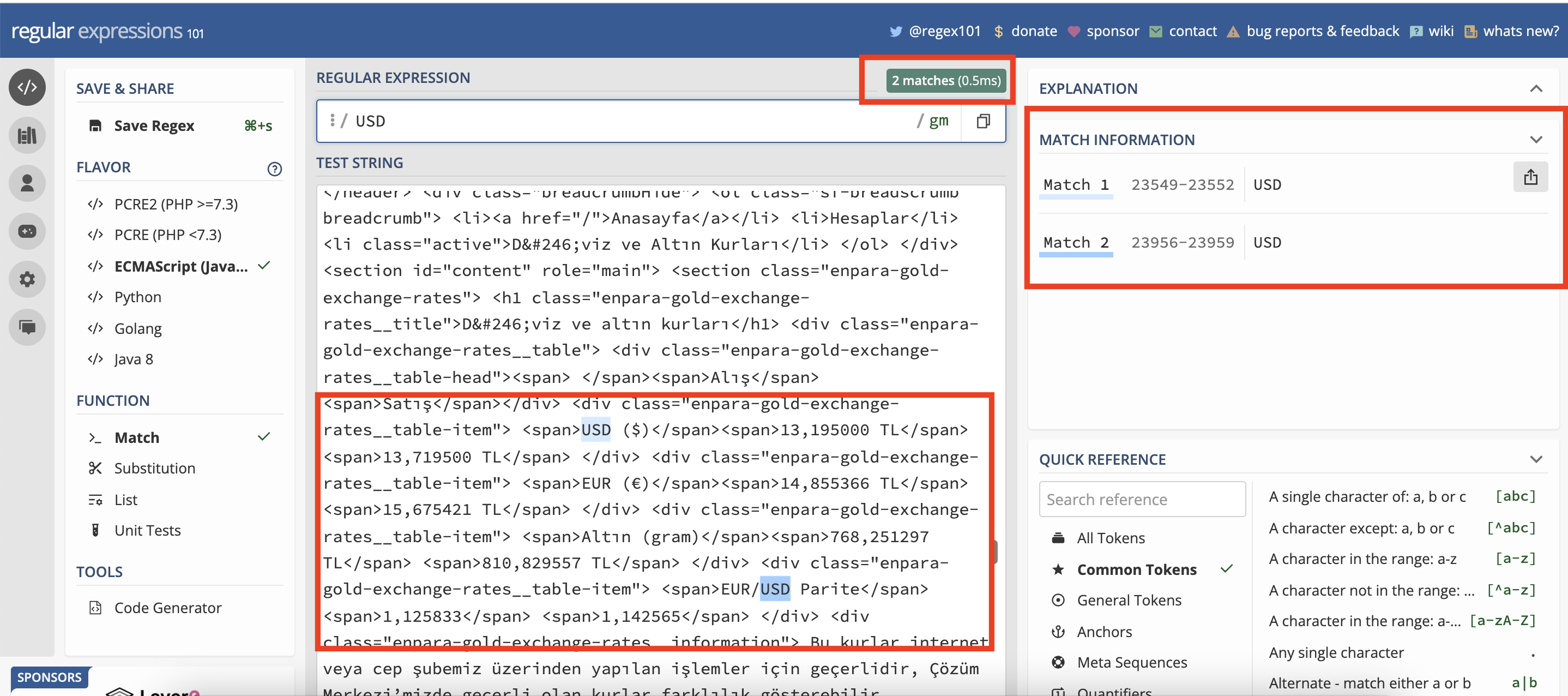
USD regex’i ile eşleşen 2 yer tespit edildi. Bunu gösterme amacım ilk olarak eşleşme yapacağımız yeri gözlemlememiz gerektiğini anlatmaktı. Şimdi HTML tag(örn: div, span) ve attribute(örn: class) alanlarından yararlanarak regex’i oluşturalım. Kaynak koduna dikkat ettiğimizde enpara-gold-exchange-rates__table-item adında bir sınıf tanımlanmış. Regex’in yakalamaya başlaması için bu sınıfı, bitişi için de enpara-gold-exchange-rates__information sınıfını kullanabiliriz.
/enpara-gold-exchange-rates__table-item(.*?)enpara-gold-exchange-rates__information/g
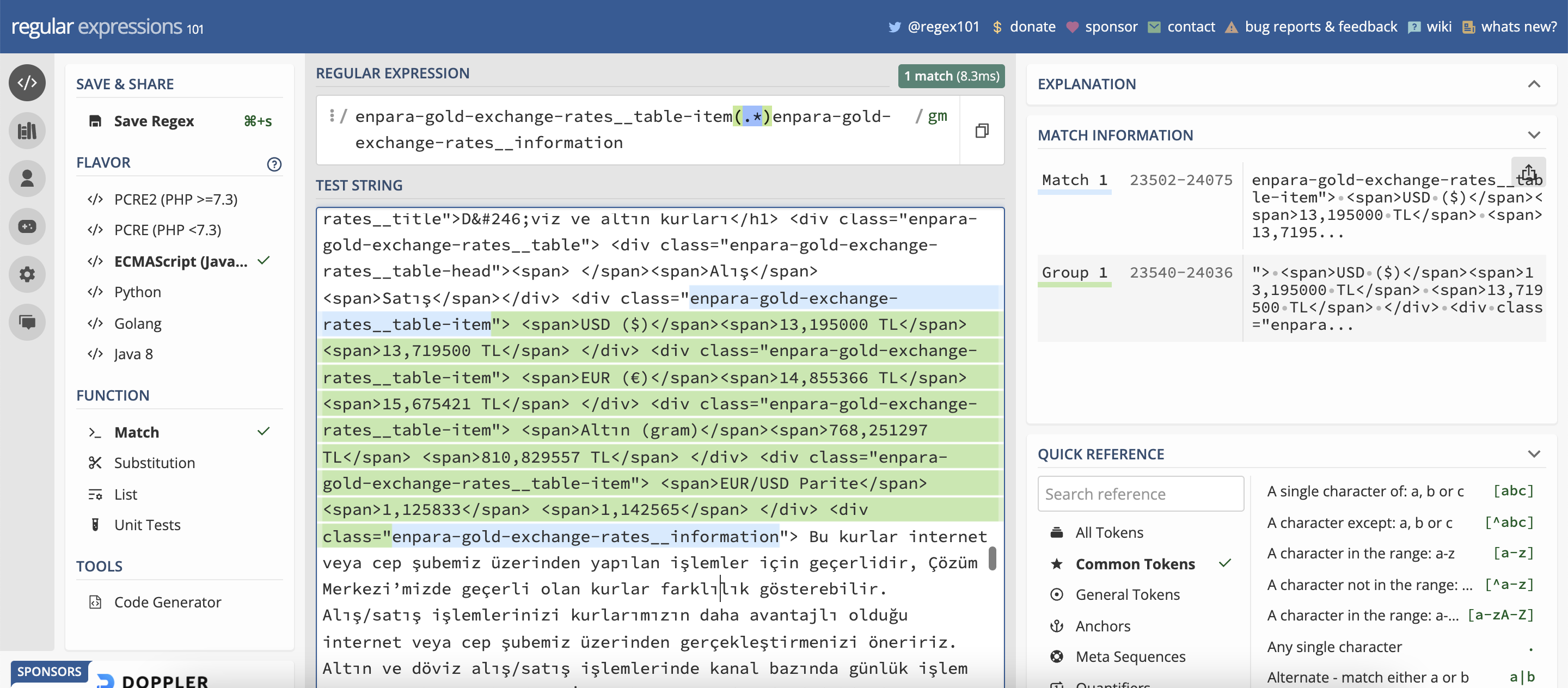
Oluşturduğumuz regexi açıklayalım:
- enpara-gold-exchange-rates__table-item gördüğün zaman yakalamaya başla.
- (.*?) gördüğün tüm karakterleri yakala ve bir grup içine al.
- enpara-gold-exchange-rates__information gördüğün zaman yakalamayı bitir.
Şimdi regex’te bir aralık belirledik. Tüm ifadeleri bir tane regex yazarak elde etmeye çalışmak yazdığımız regex’i karmaşıklaştıracaktır. Bu nedenle burada yakaladığımız daha küçük alanda çalışacak yeni bir regex yazabiliriz. Ayrıca daha küçük bir alanda çalışacağını bildiğimiz için çok daha genel bir regex yazma imkanına sahip olduk.
1
/([0-9,]+)\sTL/g
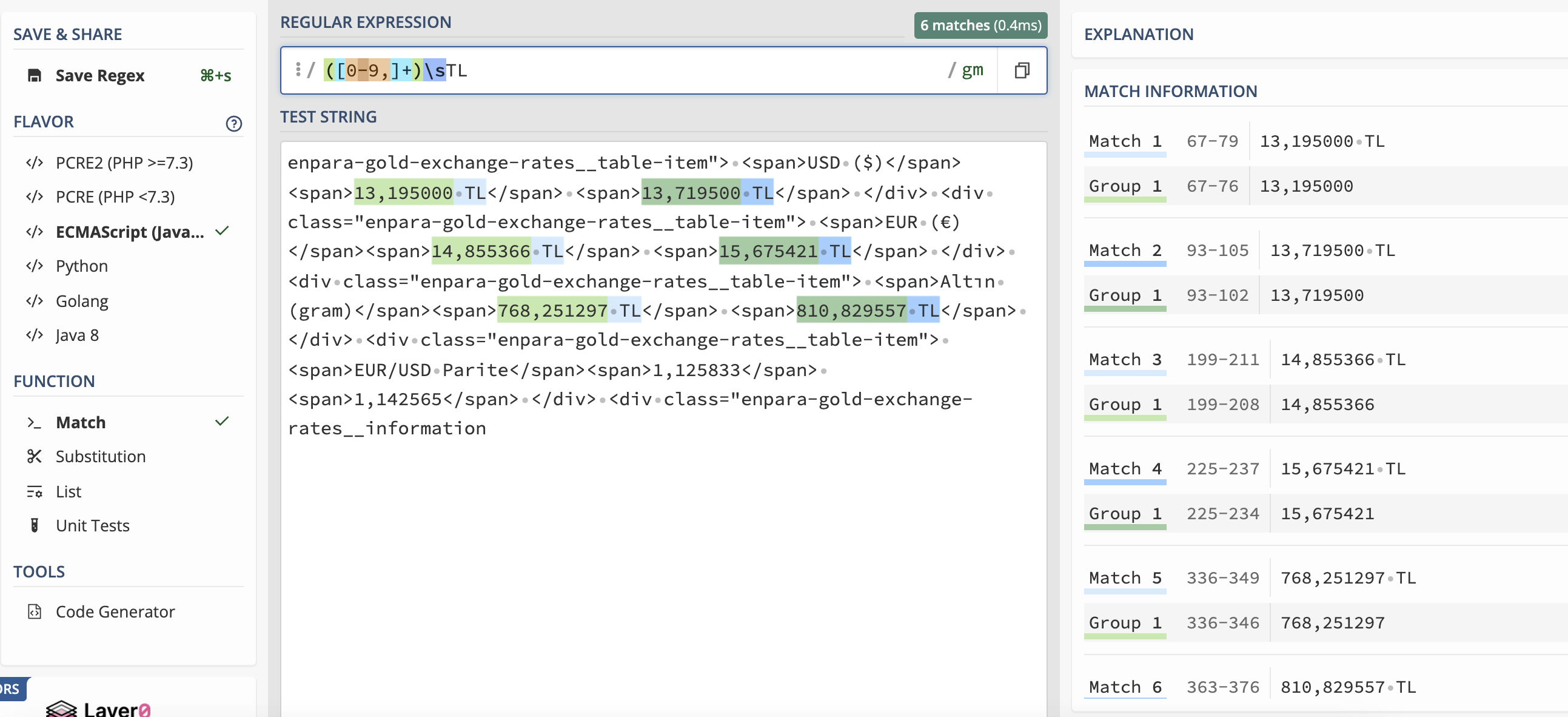
Süper! Artık elimizde istediğimiz alanlar var. Yazdığımız basit iki tane regex ile istediğimiz sonuca ulaştık. Yazdığımız son regex’i açıklayalım ve kodlamaya geçelim.
- ([0-9,]+) 0-9 arasındaki sayıları ve virgül(,) işaretini gördüğünde yan yana kaç kez tekrar ediyorsa yakala bunları bir gruba al.
- \s+ yan yana olan tüm white space karakterleri yakala
- TL ifadesini yakala
Düzenli ifadelerle ilgili eksiğiniz olduğunu düşünüyorsanız sizi şöyle alalım:
Node.js ile Kodlama
Artık web scraping için tüm araçlar hazır. Yapacağımız işlem yazdığımız regex’leri String metotlarını kullanarak uygulamamıza eklemek. Uygulamamızda HTML verisini çekmiştik. Şimdi bir fonksiyon tanımlayıp ayıklama işlemlerini yapalım.
1
2
3
4
5
6
7
8
9
10
11
12
13
function extractWithRegex(body) {
let extractedInfo = body.match(/enpara-gold-exchange-rates__table-item(.*?)enpara-gold-exchange-rates__information/g);
if (!extractedInfo) throw new Error("Regex is not match any values. Please check your regex");
extractedInfo = extractedInfo[0].match(/([0-9,]+)\s*TL/g);
if (!extractedInfo) throw new Error("Regex is not match any values. Please check your regex");
for (let i = 0; i < extractedInfo.length; i++) {
extractedInfo[i] = parseFloat(parseFloat(extractedInfo[i].replace(/\s*TL/g, "").replace(/,/g,".")).toFixed(3));
}
return extractedInfo;
}
Kodları adım adım açıklayalım:
- extractWithRegex adında, parametre olarak çektiğimiz HTML body’sini alan bir fonksiyon tanımlandı.
- body bir string değişken olduğu için match() metoduyla, ilk yazdığımız regex ifadesini içinde aradık.
- Eğer match metodu bir eşleşme bulursa bir dizi, bulamazsa null döneceğini bildiğimiz için sonucu atadığımız extractedInfo değişkenini kontrol ettik. Eğer null ise bir hata fırlatmasını sağladık.
- Ardından bu kez ayıklanmış daha küçük parça içinde ikinci regex’i arattık.
- Yine aynı şekilde eşleşme bulamazsa hata fırlatmasını sağladık.
- Ardından elde ettiğimiz verileri replace metoduyla temizleyip istediğimiz formata getirdik ve parseFloat ile sayısal ifadelere dönüştürdük. İki tane parseFloat kullanma nedenimiz, toFixed metodunun String döndürmesidir. Sonucu sayısal istediğimiz için tekrar dönüştürdük.
- En sonda da bulduğumuz sonuçları return ile döndürdük.
Böylece 6-7 satır kodla veri ayıklama işlemimizi bitirdik. extractWithRegex fonksiyonunun çıktısı bir dizi olacaktır.
1
[ 13.195, 13.72, 14.855, 15.675, 768.251, 810.83 ]
Burada dikkat ederseniz değerler istediğimiz gibi sayısal değil ve sonlarında TL ifadesi yer alıyor. Bu verileri JSON objesine yazarken düzenleyebiliriz. Şimdi bu verileri en başta söylediğimiz gibi JSON formatına dönüştürelim. Bunun için de ayrı bir fonksiyon tanımlayalım.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
function createJSON(info) {
let usd = {}, eur = {}, gold = {};
if (!Array.isArray(info)) throw new Error("info parameter must be an Array");
if (info.length >= 2) {
usd.buy = info[0];
usd.sell = info[1];
}
if (info.length >= 4) {
eur.buy = info[2];
eur.sell = info[3];
}
if (info.length >= 6) {
gold.buy = info[4];
gold.sell = info[5];
}
return {
usd,
eur,
gold
};
}
createJSON fonksiyonumuzda bazı kabullerimiz oldu. Bu kabuller; info parametresinin bir dizi olması gerektiği ve bu dizinin değerlerinin sırasının önemli olduğudur. Bu kabulleri belirlerken, web sitesinde çektiğimiz verilerin sıralamasından ve extractWithRegex metodunun çıktısını dikkate aldık. Son olarak tüm uygulamamız aşağıdaki halini aldı.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
const request = require("request-promise");
try {
getExchangeInfo();
} catch (err) {
console.error("ERR", err);
}
async function getExchangeInfo() {
let body = await request({
url: "https://www.qnbfinansbank.enpara.com/hesaplar/doviz-ve-altin-kurlari",
method: "GET"
});
let info = extractWithRegex(body);
console.log(createJSON(info));
}
function extractWithRegex(body) {
let extractedInfo = body.match(/enpara-gold-exchange-rates__table-item(.*?)enpara-gold-exchange-rates__information/g);
if (!extractedInfo) throw new Error("Regex is not match any values. Please check your regex");
extractedInfo = extractedInfo[0].match(/([0-9,]+)\s*TL/g);
if (!extractedInfo) throw new Error("Regex is not match any values. Please check your regex");
for (let i = 0; i < extractedInfo.length; i++) {
extractedInfo[i] = parseFloat(parseFloat(extractedInfo[i].replace(/\s*TL/g, "").replace(/,/g,".")).toFixed(3));
}
return extractedInfo;
}
function createJSON(info) {
let usd = {}, eur = {}, gold = {};
if (!Array.isArray(info)) throw new Error("info parameter must be an Array");
if (info.length >= 2) {
usd.buy = info[0];
usd.sell = info[1];
}
if (info.length >= 4) {
eur.buy = info[2];
eur.sell = info[3];
}
if (info.length >= 6) {
gold.buy = info[4];
gold.sell = info[5];
}
return {
usd,
eur,
gold
};
}
Toplamda 50 satırlık kodla bir web sitesinden veri çekme, regex ile ayıklama ve formatlama işlemlerini yapmış olduk. Burada geliştirdiğimiz fonksiyonlarda bazı hatalar fırlattık. Bu nedenle try-catch kullanarak bu hataları yakalamak uygulamanın çökmesini engellemek için önemlidir. Bu nedenle getExchangeInfo() fonksiyonunu çağırırken try-catch arasına aldık.
Bir web sitesinden veri çekme işlemi, o web sitesinin HTML kodlarına çok bağımlıdır. Eğer sitede bir değişiklik olursa yüksek ihtimalle yazdığınız kod çalışmayacaktır. Web Scraping yaparken bu konuyu göz önünde bulundurmanız önemlidir.
Bir sonraki Web Scraping makalesinde aynı işlemi cheerio modülü ile nasıl yapacağımızı adım adım anlatmaya çalışacağım. Mutlu günler :)