Regex Nedir? Nasıl Çalışır? Kullanım Amacı Nedir?
Regex konusu, yazılım hayatımız boyunca karşımıza çıkacak olan önemli bir konudur. Sadece Javascript’te değil, tüm programlama dillerinde ortak olarak kullanılan bir dildir de diyebiliriz. Dil olarak tanımlamamızın sebebi, kendine özel bir yapısının ve karakter setinin olmasından kaynaklıdır. Regex tanımına geçmeden önce söylemeliyim ki akılda kalıcı olması için sık sık kullanmanız ve örneklerle pekiştirilmesi gereken bir yapıdır.
Regex Nedir?
En temel tanımıyla bir metnin içindeki tarih, telefon, email vb. formatlı verileri tespit edip ayıklayabilmemiz için oluşturulmuş bir biçimdir. Örneğin bir websitesine kayıt olurken email alanına email formatının dışında bir veri girildiğinde sizi uyarır. İşte bu uyarıyı yapabilmek için formatın kontrolünü regex kullanarak yaparız.
Regex Kullanım Amacı
- Kullanıcı girdisinin denetlenmesi
- Bir metnin içinden istenen verinin çekilmesi
- Verilerin kullanım amacına uygun hale getirilmesi
Regex Nasıl Yazılır?
Regex yazmak için bazı karakterleri ve ne işe yaradıklarını bilmek gerekir. Bu karakterler, istediğimiz formatı oluşturmak için bize yardımcı olacak. Aşağıda tüm karakterleri tek tek inceleyeceğiz ve örneklendireceğiz. Regex denemeleriniz için regex101 sitesini kullanabilirsiniz. Bir regex tanımlarken yazacağımız karakterleri iki slash(/) arasına yazmalıyız.
/regex/g
Yukarıdaki regex örneği, metnin içinde “regex” geçiyorsa eşleşecektir. Regex101’de deneyelim.

Regex Tanımlama
Meta Karakterler
Meta karakterler, kendisi haricinde regex’te farklı anlama sahip karakterlerdir. Tek tek tanıyalım.
”.” karakteri
Satır sonu haricinde herhangi bir karakteri temsil eder. Bir örnek ile görelim.
/s.l.k/g
Bu şekilde bir regex tanımladığımızda, aslında şunu söylemiş oluyoruz:
- s ile başlayan
-
- karakteri herhangi bir karakter olan
-
- karakteri l harfi olan
-
- karakteri herhangi bir karakter olan
- son karakteri k olan
ifadeleri yakala. Bu eşleşmeye uyan metnin içinde geçen suluk, silik, salık, salak,s_l_k,s l k gibi ifadelerin tamamı yakalanır. Ayrıca asalak, isilik, asilik, sulukçu, sulukule gibi ifadeler de bir parçası eşleşen ifadeler de yakalanır. Ancak burada dikkat edilmesi gereken kısım, sadece tanımladığımız parçanın eşleşeceğidir.
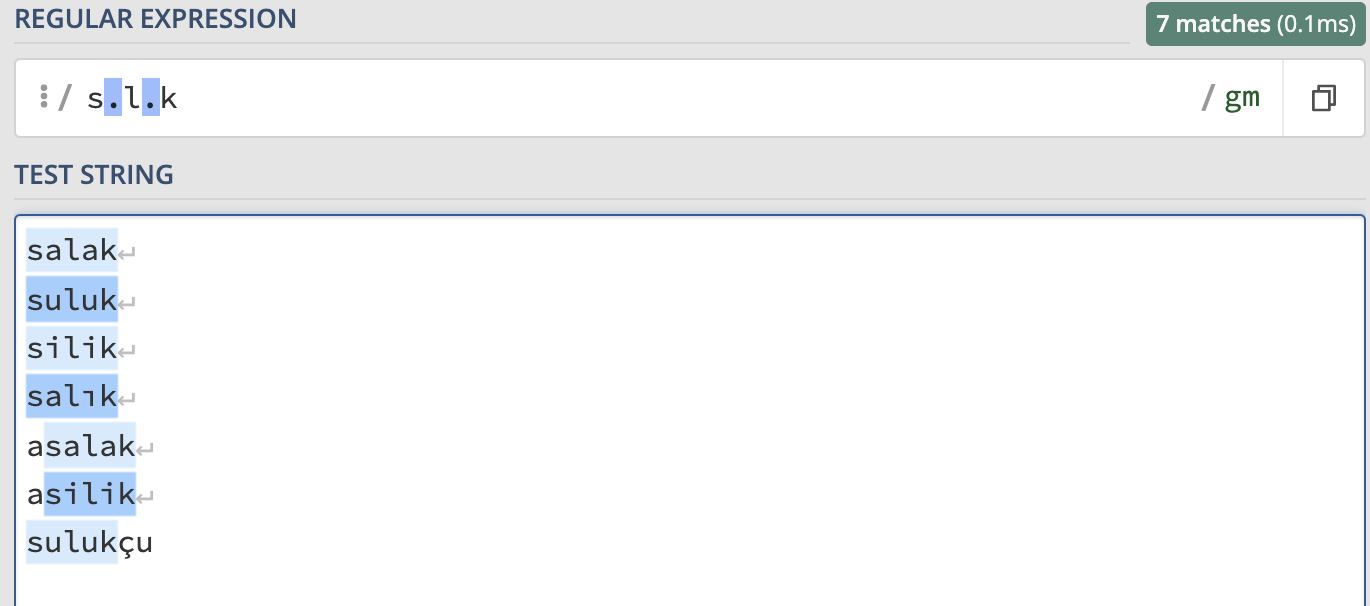
Regex . karakteri
[] yapısı
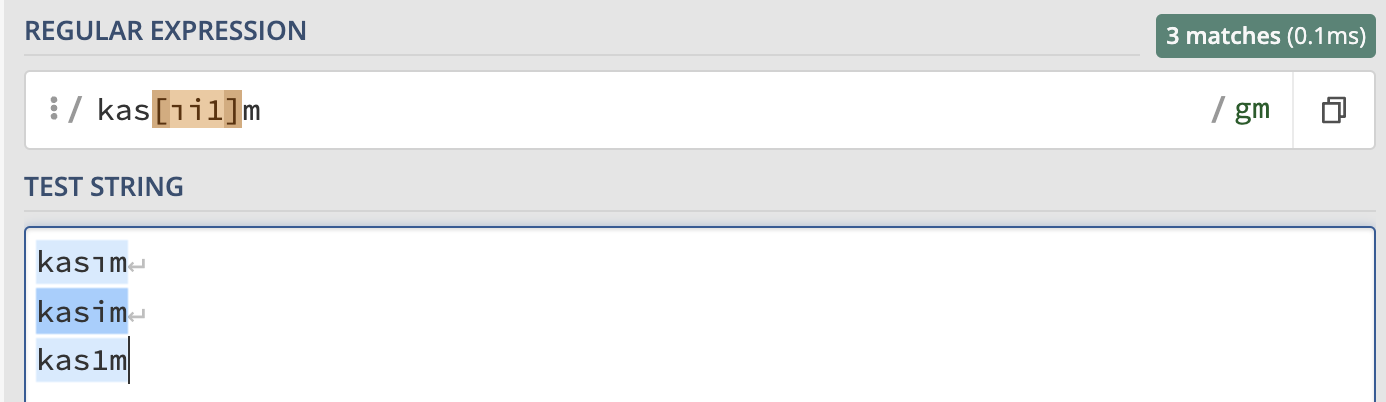
Köşeli parantezler arasına yazılan karakterlerin ifadelerin tümüyle eşleşme sağlanır. Örneğin kasım ayının ingilizce karakterlerle yazılabilme ihtimaline karşı kasim ve kas1m ifadelerinin yakalanmasını istersek.
/kas[ıi1]m/g
Ayrıca [] karakterlerini kullanarak bir karakter aralığı da tanımlayabiliriz. Aralık tanımlamak için - karakterinden yararlanırız. Örneğin metin içindeki sayıları yakalayan bir regex yazalım.
/[0-9]/g
Yukarıdaki regex, metnin içinde geçen 0 ile 9 arasındaki tüm rakamları yakalar.
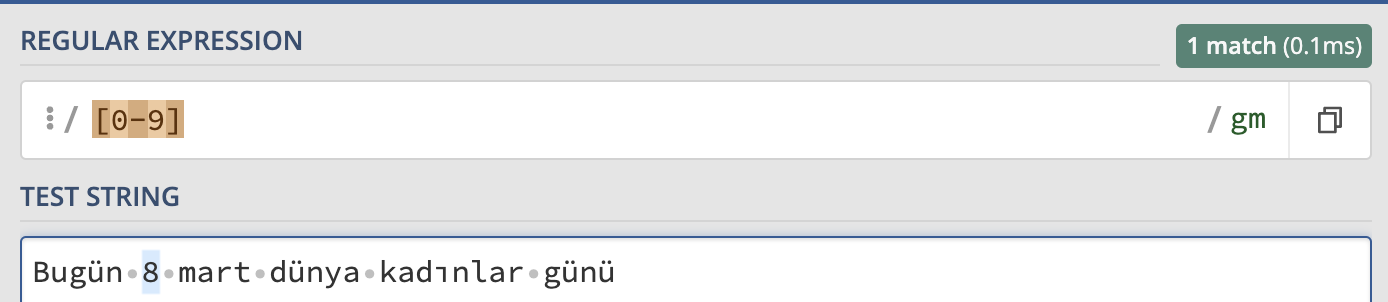
Regex - [0-9]
Ayrıca tüm küçük harfler için [a-z] ve tüm büyük harfler için [A-Z] kullanabiliriz. Bu aralıklar en geniş aralıklardır. Belli bir aralık almak istersek sınırlarını belirleyebiliriz. Örneğin [1-5] ile 1,2,3,4,5 rakamlarını yakalayabiliriz. Harfler için de aynı şey geçerlidir.
Not: [a-z] ve [A-Z] aralığında sadece İngilizce karakterler vardır. Türkçe karakterler ayrıca eklenmelidir. [a-zöçşığü] ve [A-ZÖÇŞİĞÜ] gibi.
+ karakteri
- karakteri, önünde tanımlanan ifadenin 1-sonsuz arasında tekrarlarının da yakalanmasını sağlar. Örneğin yukarıdaki sayı aralığı sadece bir sayıyla eşleşir ancak eğer aralığı aşağıdaki şekilde tanımlarsak yan yana gelen tüm rakamları tek eşleşmede yakalar.
/[0-9]+/g
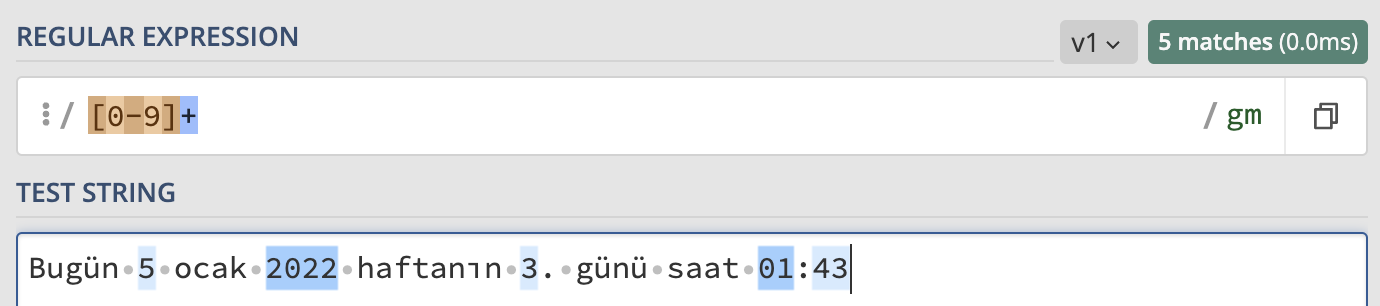
* karakteri
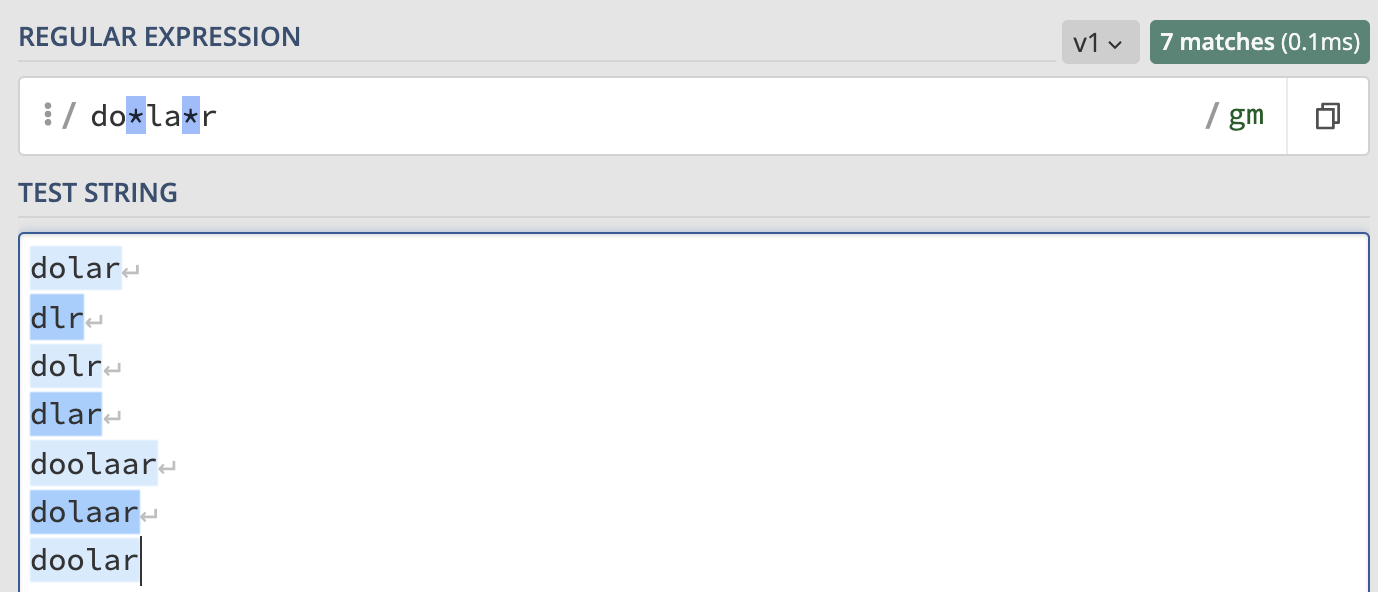
- karakteri, önünde tanımlanan ifadenin 0-sonsuz arasında tekrarlarının da yakalanmasını sağlar. Örneğin dolar ifadesinin dolar, dlr, dlar ve dolr hallerinin ve hatta dolaaar, doooolar, doolaar gibi hallerinin de yakalanmasını sağlayalım.
/do*la*r/g
? karakteri
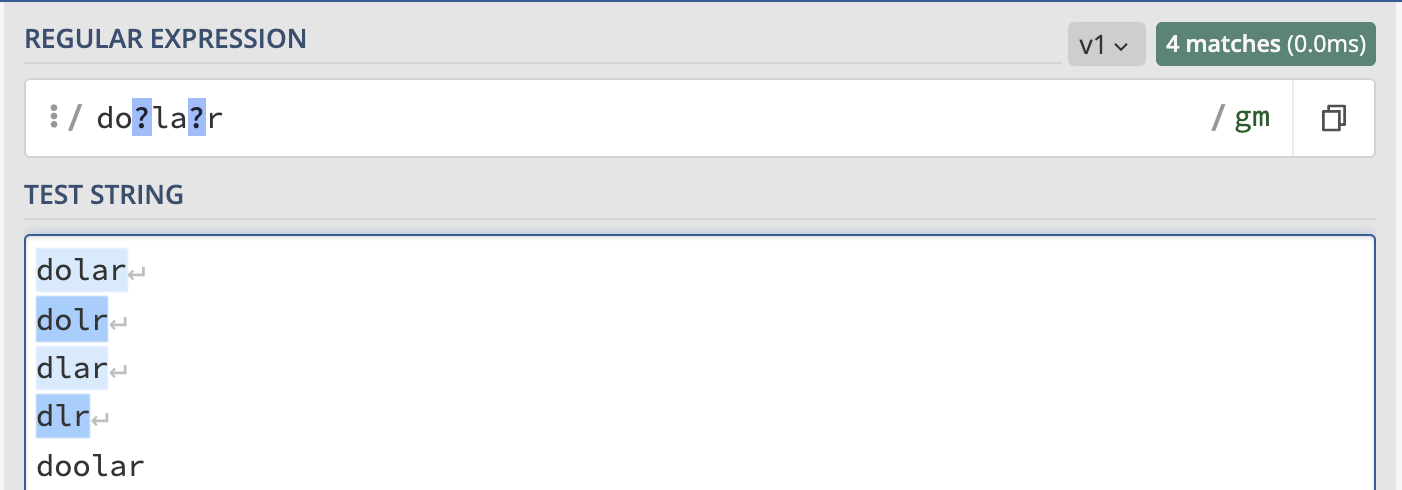
? karakteri, kendinden önceki karaktere varlığıyla yokluğu bir anlamını yükler. Örneğin dolar ifadesinde yukarıdaki gibi karakter çoklamasına izin verilmeyecek şekilde sadece karakter eksikliğinde çalışmasını istersek yazacağımız ifade do?la?r şeklinde olacaktır.
/do?la?r/g
Yukarıdaki regexi ifadesi ile yakalanacak olan kelimeler: dolar, dolr, dlar, dlr. Ancak örneğin doolar ifadesi yakalanmayacaktır.
{n,m} karakteri
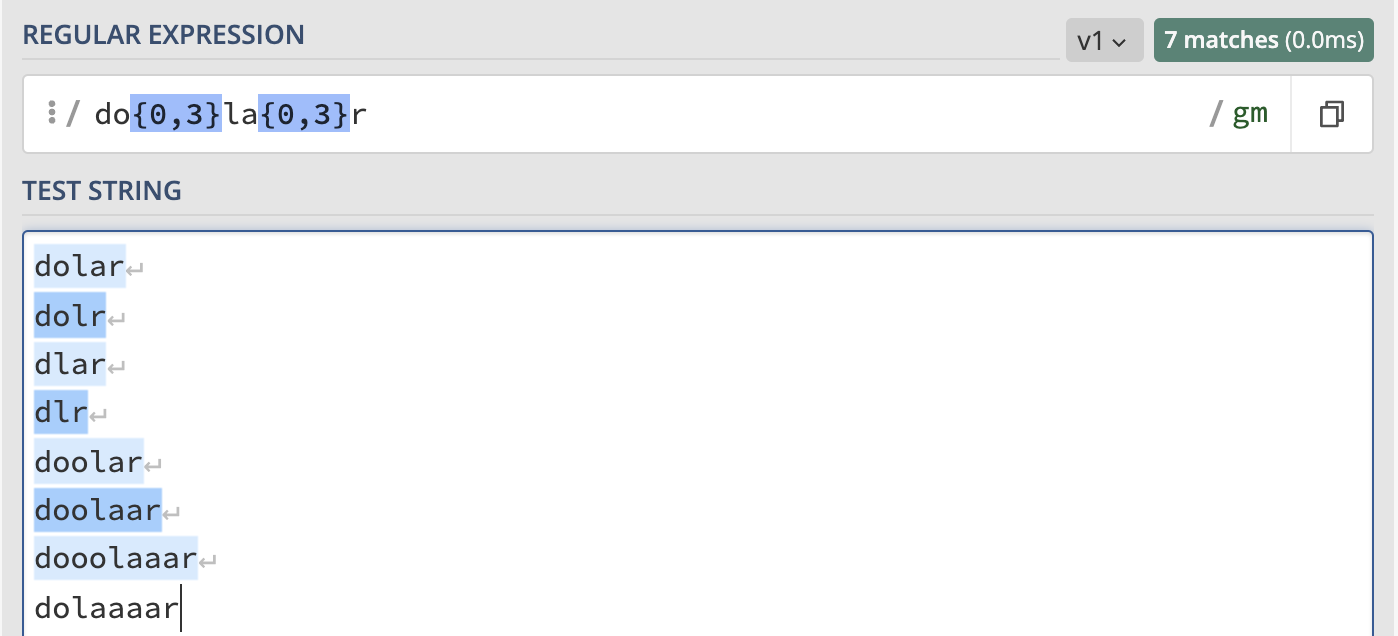
{n,m} karakteri, bir önceki karakterin n-m arasında tekrarlanması durumunda yakalar. n ve m birer sayı değerini temsil eder. Örneğin yukarıdaki * ve ? karakterleri ile kullanımını gördüğümüz dolar ifadesinin belirli tekrarları kabul ettiğimiz versiyonunu yazalım. Amacımız * karakteri gibi sonsuz sayıda tekrarı kabul etmemek fakat ? karakteri gibi de sadece bir kez kullanımıyla da yetinmemek olduğu durumlarda yazacağımız regex şu şekilde olacaktır.
/do{0,3}la{0,3}r/g
Yukarıdaki regex ifadesi, o ve a karakterlerinin hiç yazılmaması ya da en fazla 3 kez tekrarlanması durumunda dolar ifadesinin yakalanmasını sağlayacak. Ancak o veya a karakterlerinden biri 3 defadan fazla kullanılırsa yakalamayacak.
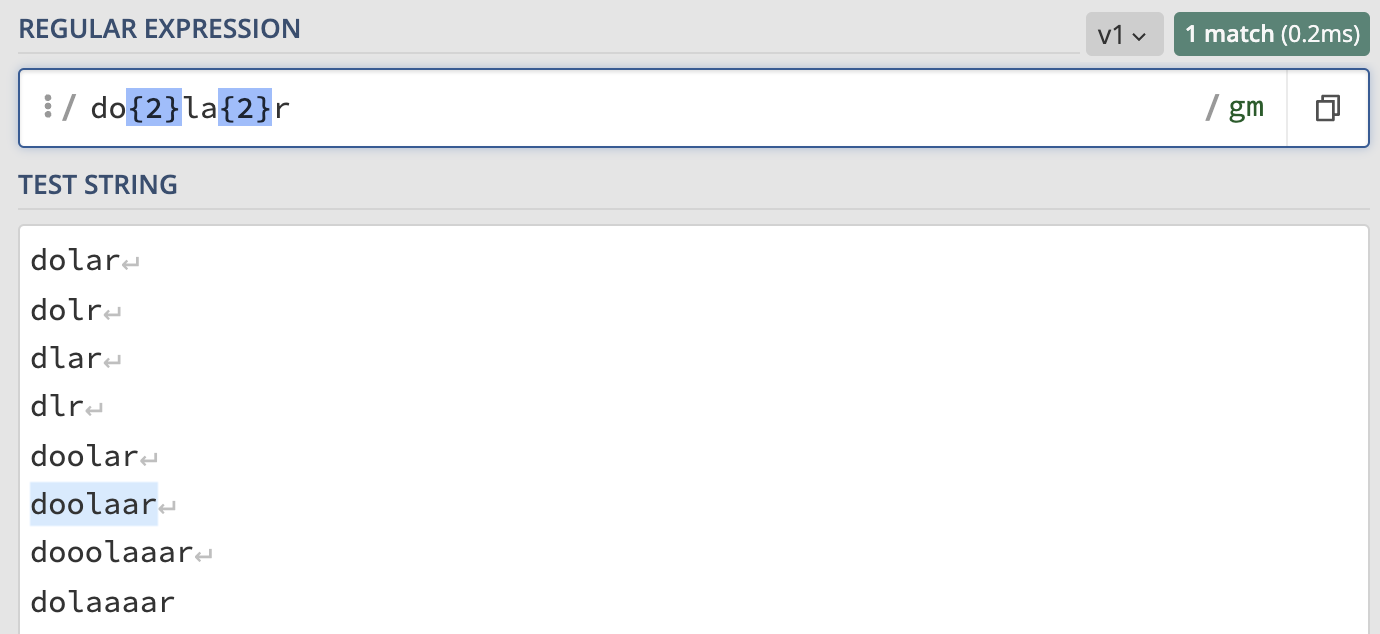
Ek olarak {} karakteri arasında bir aralık yerine tek bir sayı da verebiliriz. Bu durumda önceki karakterin net olarak kaç kez tekrarlanacağını söylemiş oluruz. Eğer bu tekrar sağlanmazsa regex ifadesi kelimeyi yakalamayacaktır. Bunun da bir örneğini görelim.
/do{2}la{2}r/g
Son olarak {n,} şeklinde bir kullanım da mevcuttur. Bu durumda n tekrardan başlayarak sonsuz tekrarı yakalayan ifadeler yazabiliriz. Bu yapıyı * ve + karakterlerinin karşılıklarını yazarak pekiştirebiliriz.
-
- karakterinin karşılığı {0,}
-
- karakterinin karşılığı {1,}
olarak ifade edebiliriz.
^ karakteri
^ karakteri, metnin başını ifade eder. Eğer metnin başında kontrol etmek istediğimiz bir ifade varsa bu durumda kullanırız. Örneğin metnin büyük harfle başlayıp başlamadığını yakalayan bir regex yazalım.
/^[A-ZÖÇŞİĞÜ]/g
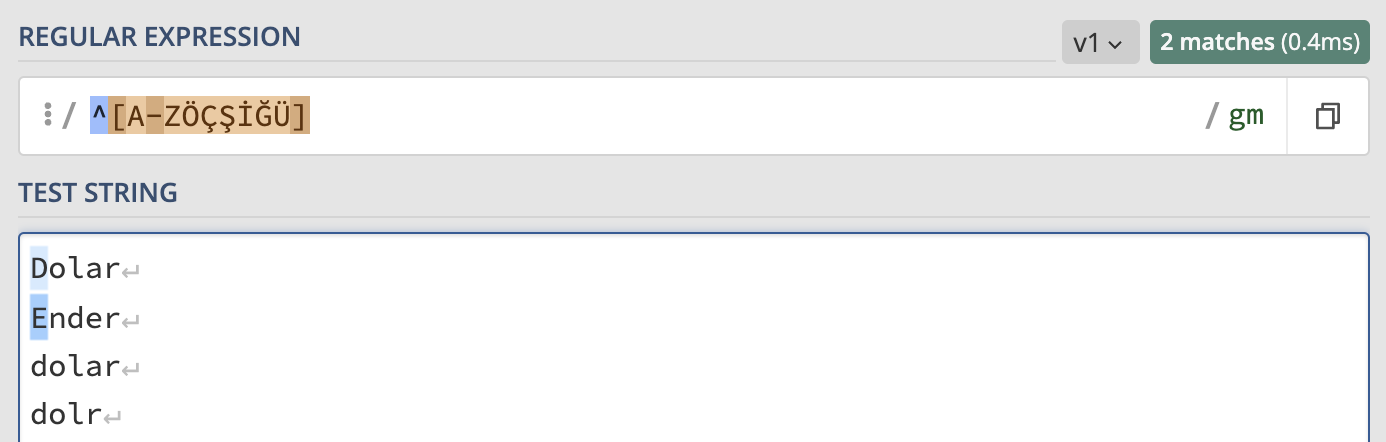
Eğer köşeli parantezlerin içine yazılan karakterlerin başına ^ karakteri eklenirse girilen karakterler ya da aralıklar haricinde kalanları yakalar. Örneğin büyük harfle ya da sayıyla başlamayan metinleri yakalamak istersek.
/^[^A-ZÖÇŞİĞÜ0-9]/g
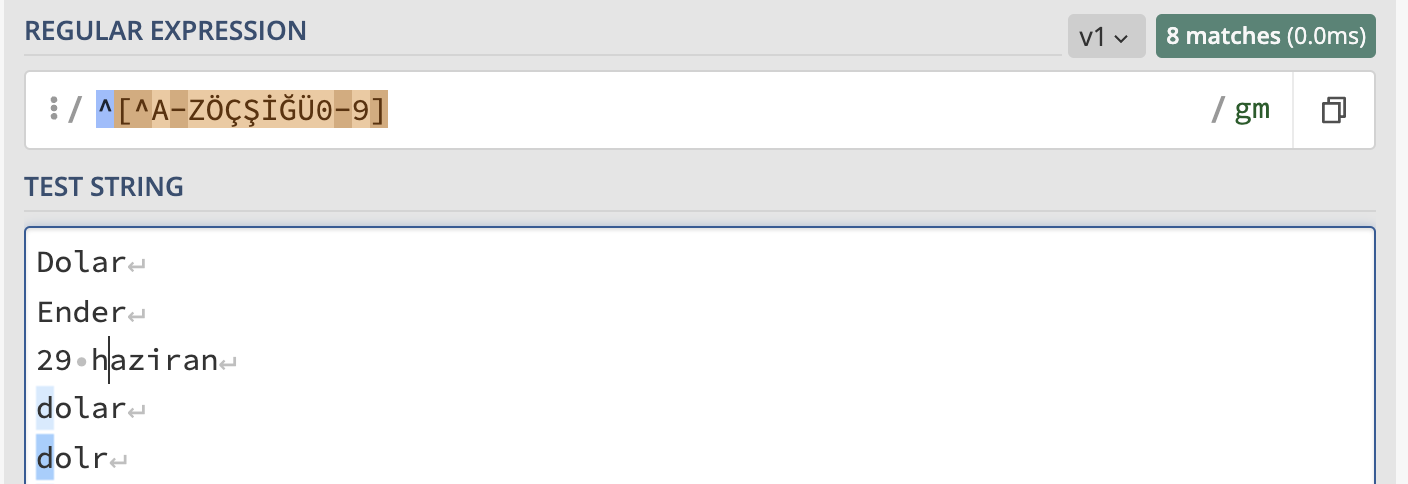
\ karakteri
\ karakteri, bir kaçış karakteridir. Regex’te özel bir göreve sahip karakterlerin özel görevlerinin değil de kendi anlamlarında kullanabilmemizi sağlar. Örneğin bir “[ÇÖZÜLDÜ] Regex öğrenme görevi”, “[BEKLEMEDE] Node.js öğrenme görevi” yapısına sahip başlıklarımız olduğunu düşünelim. Bu başlıklardan [] arasındaki ifadeleri ayıklamak istersek, oluşturacağımız regex’te köşeli parantezlerin regex’teki özel görevlerine değil, kendi anlamlarına ihtiyacımız olacak. Dolayısıyla yazacağımız regex şu şekilde olmalıdır.
/^\[.*\] .*/g
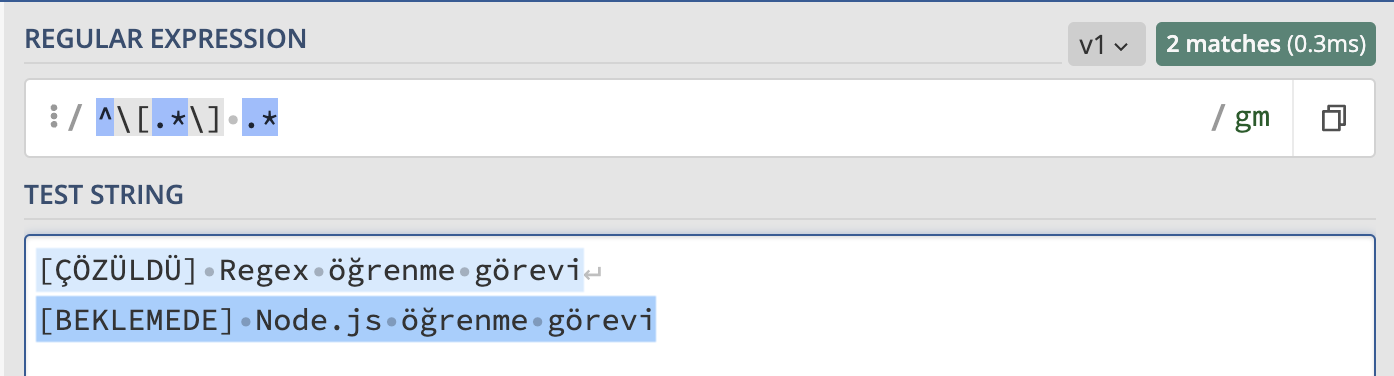
Yukarıdaki örnekte ayıklama işlemi değil aslında bir yakalama işlemi yapmış olduk. Eğer ayıklama yapmak istersek bu durumda gruplama işlemi yapan parantezlere ihtiyacımız olacak.
() yapısı
Parantezler, yazdığımız regex ifadelerinde ayıklamak istediğimiz alanları gruplayarak ana ifadeden ayrı şekilde ayırmamıza yarar. Bir üstteki örnekteki köşeli parantezler arasındaki ifadeleri ayıklamak istersek şöyle bir regex yazmamız gerekir.
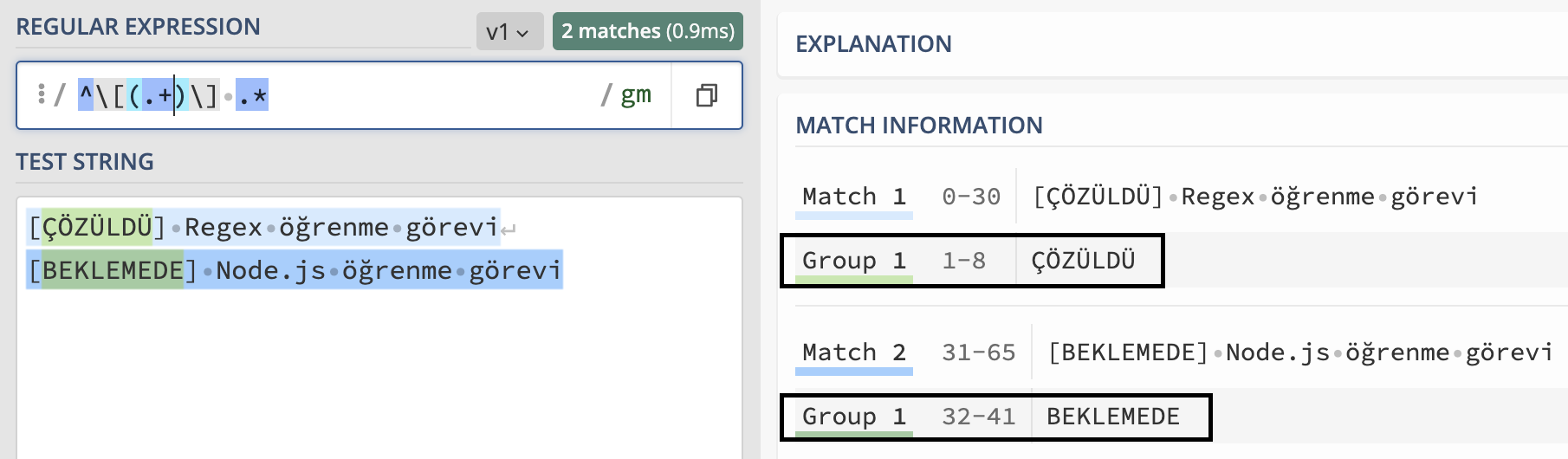
/^\[(.+)\] .*/g
Yukarıdaki regex’i açıklayalım:
- ^\[ -> metnin köşeli parantez ile başlaması gerektiğini belirttik
- (.*) -> köşeli parantez açıldıktan sonra tüm karakterleri yakalayıp bir gruba koymasını söyledik
- \] -> köşeli parantezin kapatıldığı an gruplamanın biteceğini söyledik.
- boşluk -> köşeli parantez kapatıldıktan sonra bir boşluk olması gerektiğini belirttik.
- .* -> metnin sonuna kadar var olan tüm karakterleri yakalamasını söyledik.
$ karakteri
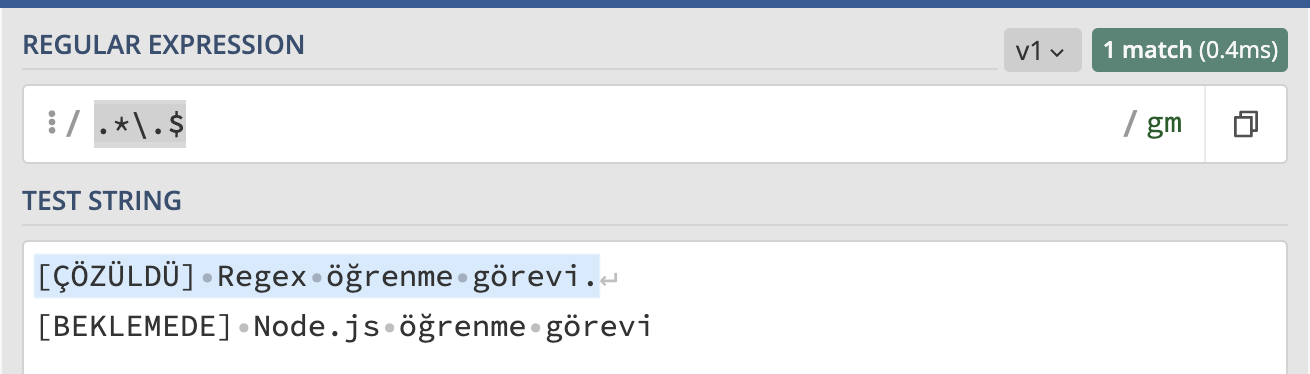
$ karakteri, metnin sonunu ifade eder. Eğer metnin sonunda kontrol etmemiz gereken bir ifade varsa $ karakterini kullanırız. Örneğin cümlenin nokta ile bitip bitmediğini kontrol eden bir regex yazalım.
/.*\.$/g
Oldukça basit öyle değil mi? :)
Karakter Etiketleri
\s etiketi
\s etiketi, white space karakterleri(boşluk, tab vb.) temsil eder. Regex’te boşluk ifadesi genelde yukarıdaki örnekte olduğu gibi değil de \s ifadesi ile belirtilir. \s etiketinin karşılığını regex ile yazmaya çalışırsak:
/[ \n\t\r\f]/g
\S etiketi de \s etiketinin tersini ifade eder.
/[^ \n\t\r\f]/g
\d etiketi
\d etiketi herhangi bir rakamı ifade eder. Regex karşılığı aşağıdaki gibidir:
/[0-9]/g
Tersi \D etiketidir. Yani rakam olmayan karakterleri ifade eder.
/[^0-9]/g
\w etiketi
\w etiketi, harfleri, rakamları veya _ karakterini temsil eder. Türkçe harfleri yakalamaz.
/[A-Za-z0-9\_]/g
Tersi \W etiketidir. Harf, rakam ya da _ karakteri hariç diğer karakterleri temsil eder.
/[^A-Za-z0-9_]/g
Regex konusuna sıkı bir başlangıç yaptık. Artık birçok regex ifadesinin ne iş yaptığını kolayca anlayabilirsiniz. Tabii tüm bu gördüğümüz ifadeleri bolca pratikle beslemek gerekir.
Egzersizler
- Bir girdinin email adresi olup olmadığını yakalayan regex ifadesi yazınız.
- gg.aa.YYYY formatında yazılan tarihlerdeki gün, ay ve yıl alanlarını ayrı gruplara alan regex yazınız.
<a href="http://endrcn.dev">endrcn.dev</a>HTML etiketinde href alanının değerini ve etiket içeriğini ayrı gruplara çıkaran regex yazınız.- ad ve soyad inputuna girilen ad soyad ifadesinde baş harflerin büyük olup olmadığını kontrol eden regex yazınız. (Örn: Ender Can)